One bug, eight fixes, and the cost of cognitive debt
AI can accelerate implementation and repairs, but it does not replace the deliberate thinking needed to catch requirements that were never stress-tested.
It all started from a Teams message I received from a colleague.
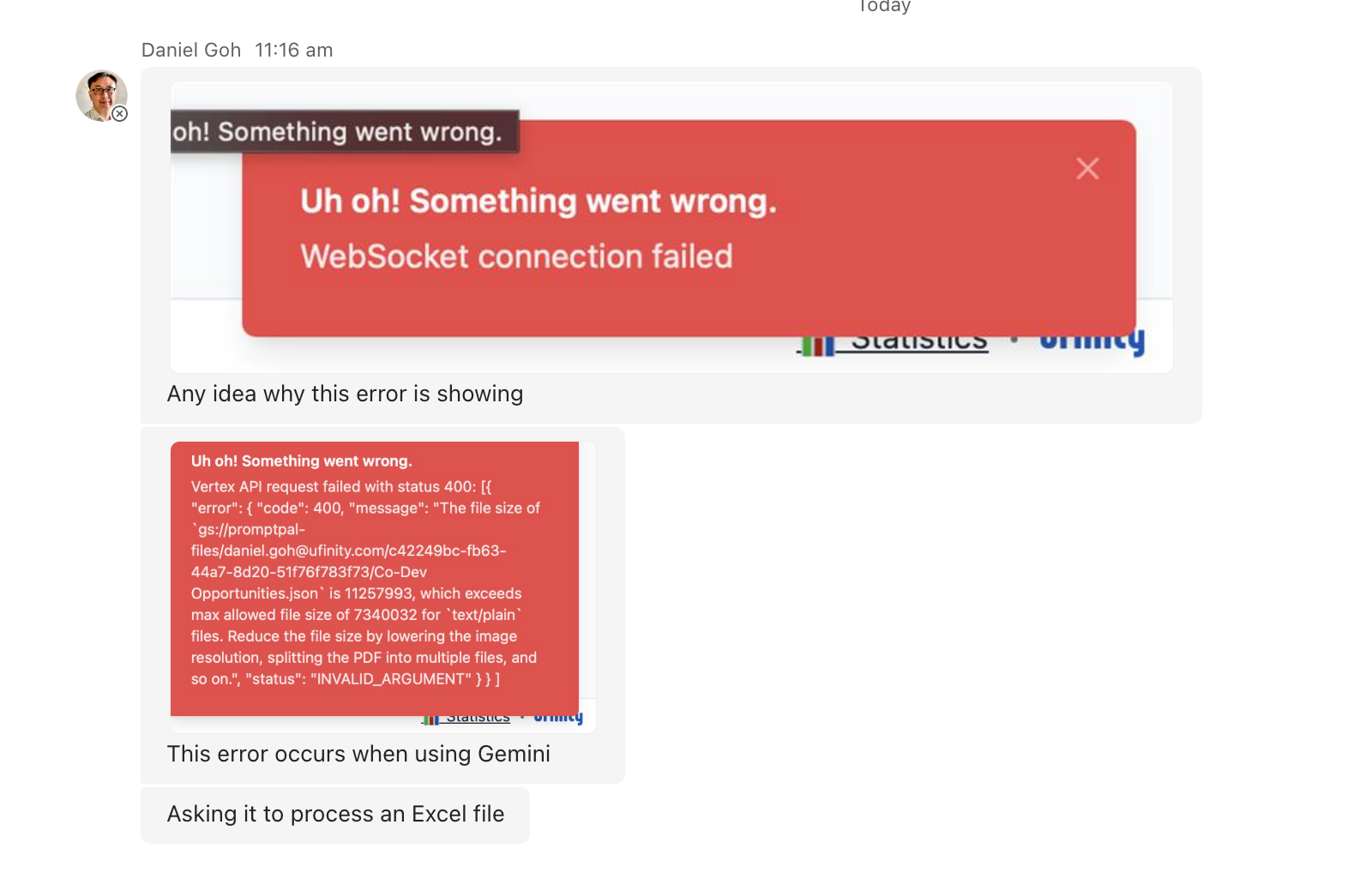
Daniel, a colleague at Ufinity, had uploaded an Excel file into PromptPal (an internal AI tool I built for staff to work with project and customer data securely), and the app crashed. Two error messages, with one mentioning a file size exceeding a maximum limit.
My first reaction was confusion. PromptPal already has a file size limit mechanism to prevent such a situation. So how did this one slip through?
After some thinking, I connected the pieces. After all, when a user uploads a spreadsheet, PromptPal does not send the Excel file directly to the AI model. Instead, it converts it into a text-based format (JSON) that the model can actually read, and uploads that converted version instead. This conversion happens silently behind the scenes.
Daniel's Excel .xlsx file had passed the upload limit check just fine. However, the converted output had ballooned to over 11 MB, well past the enterprise AI service's 7 MB limit for each text file. So, while the check was in place, it ended up checking the wrong thing.
I had built this feature in December 2025, as part of a wave of Office file support I was eager to close out before the year ended. AI-assisted development had been accelerating my output for months by that point, and the Excel conversion worked for every file I tested with. It felt done. I shipped it and moved on. Five months later, Daniel's message showed me what "done" had actually meant.
When it rains, it pours
The immediate solution was to split the converted output into multiple smaller files, each under the size limit, with each part repeating the relevant column headers so it could be read independently. I used an AI coding agent (Codex, GPT 5.5) to implement and verify the fix. It worked, and the upload no longer crashed.
I thought I was done. Then I started testing with larger files and noticed something: even moderately sized spreadsheets were taking a really long time to process, and the upload screen gave no indication of what was happening. A static "Extracting spreadsheet data..." message sat there with no movement. Was it processing? Had it failed silently? There was no way to tell. So I added live progress reporting from the conversion process: which sheet was being processed, which row, how many remained.
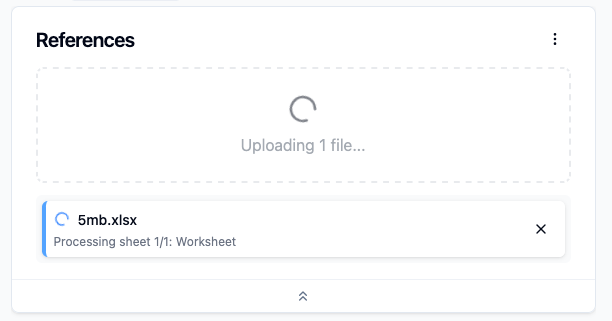
But, even with progress visible, the processing time was still taking far longer than felt reasonable. The bottleneck turned out to be in how the app verified that each growing chunk of output still fit under the size limit: it was recalculating the entire chunk's size after every single row was added. Seeing that coding inefficiency, I switched it to a leaner approach that let the app measure each row's contribution just once, removing the recalculation loop entirely.
Then something stranger happened. I tested with a small file, just 40 KB, expecting it to breeze through. It expanded to nearly 9 MB after conversion. I stared at the output for a moment before it clicked: Excel can sometimes apply invisible formatting to far more cells and columns than actually contain data. The spreadsheet looked small, but behind the scenes, it had formatting applied across thousands of empty columns. The converter was faithfully preserving all of it.
The fix was also straightforward here: strip out the empty content to cut the output size. But it also made me uneasy. How many users had uploaded files like this over the past five months without realising the converted version was bloated with nothing?
Cracks that started amplifying
At this point I had been at it for a while and started noticing issues that had nothing to do with Daniel's initial bug report, things that had been present since December and simply never surfaced.
I even found a new race-condition bug, where upon uploading two Excel files at the same time, the second file's converted content was identical to the first. Turns out, with the fixes that AI pushed, the internal process that handles conversion was shared between both uploads, and it had no way to match each result back to the correct file. So when both conversions finished, both files received whichever result arrived first.
This one really did give me pause. A silent data integrity issue, which is basically invisible until the exact right conditions lined up.
The requirement I did not stress-test
What stays with me is not the technical cascade. Each fix was individually reasonable, and the AI coding agent handled all of them in roughly two hours. What stays with me is that the cascade was fairly predictable, and I did not catch it beforehand.
The original requirement felt complete: let users upload Excel files by converting them to a format AI models can process. I validated that the conversion worked for the files I tested with. I did not ask what happens when the converted output exceeds the size limit, or when a small file expands because of invisible formatting. None of these are exotic scenarios. They are the kind of possibilities that surface when you sit with a requirement a bit longer and explore it from different angles (with or without AI), before committing to an implementation.
Building at double speed, thinking at half
AI agents helped me ship the feature in December. AI agents helped me repair it in May. In neither case did they prompt me to pause and deeply reflect about what could go wrong. That responsibility was mine, and the same momentum that made December's shipping spree feel so productive is what carried me past the deeper thinking that would have caught these problems before they reached users.
There is a growing sentiment that AI-assisted engineering means you “no longer need to read the code”. For personal tools or throwaway prototypes, maybe. But one of the fixes the agent produced introduced the concurrency bug that silently corrupted file content. I caught it because I was reading through the code after the session, not because a test flagged it. When you are shipping software that other people rely on, "the AI wrote it and it passed the tests" is not the end of your responsibility. Someone still has to understand the system well enough to know which questions to ask.
When building is fast, the constraint moves from execution to judgment, and judgment requires a deliberate slowness that the tools do not enforce. The tooling around me has changed considerably over the past year. The need for that discipline has not changed at all.